今天我們繼續來分享後半段的程式碼~

方法1:從頭訓練
實例化優化器
實例化損失函數
開始訓練(取得X,Y數據、計算損失、取得梯度、更新模型)


方法2
訓練設置

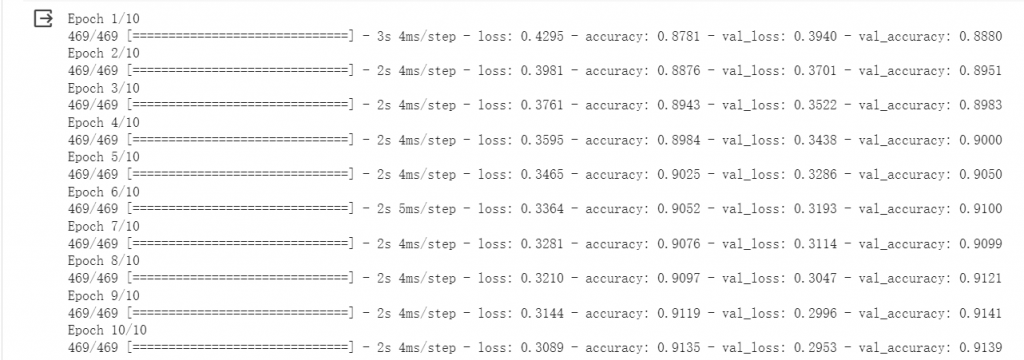

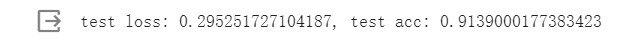
測試損失: 02952……
**測試準確度:**0.9139……




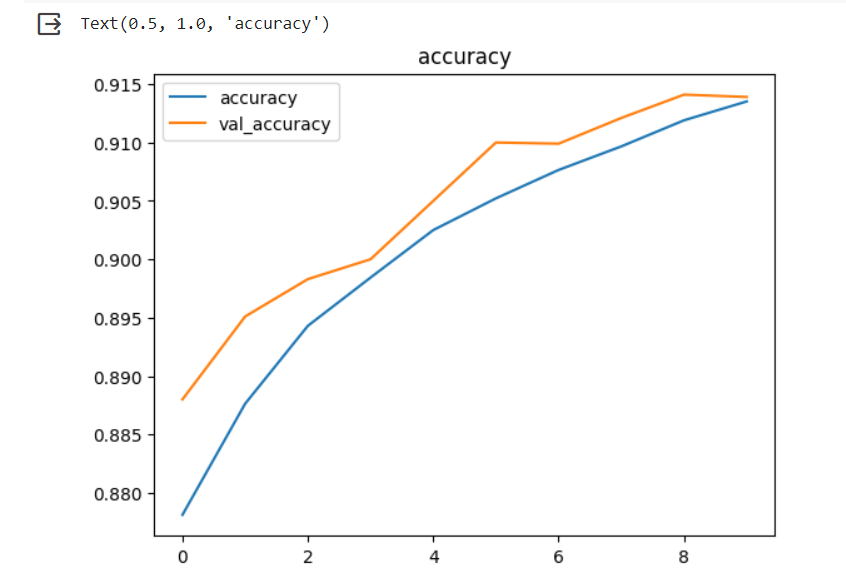

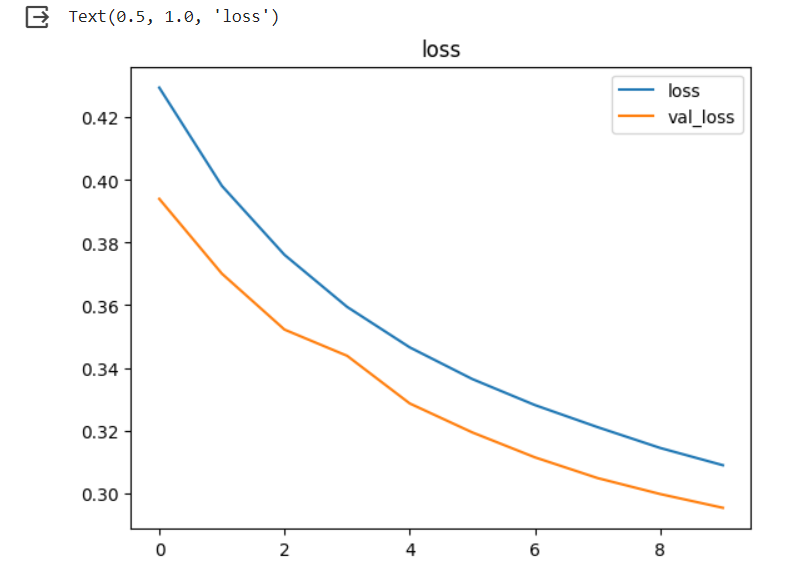

模型預測


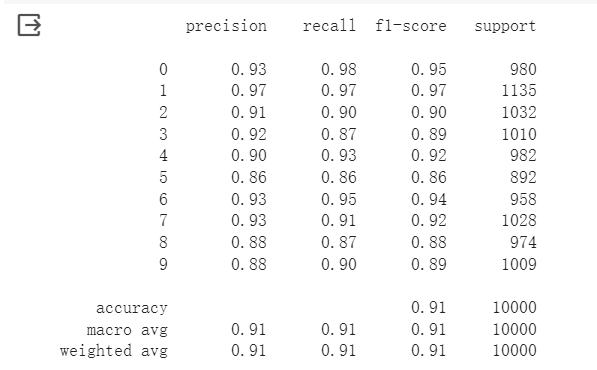
分類報告

混淆矩陣
行 : 真相
欄 : 預測




僅保存和載入權重
載入權重之前重建模型
這次透過Keras來訓練MINST資料集,因為需要訓練的epoch更多,模型也比較多,相較於前幾次的LSTM實作跟訓練iris資料集,這次花費更多訓練時間跟占用比較多的空間。然後有的語法也是比較複雜,還好這次學校老師在講解的時候有說得比較仔細。


 iThome鐵人賽
iThome鐵人賽